애그리게잇
도메인 객체의 관리는 객체의 생명주기 동안 무결성을 유지하고 생명주기 관리를 위해 객체의 관계가 복잡해지는 것을 최소화하는 것이 중요합니다. 따라서 업무상 관련 있는 객체들을 묶어 경계를 명확히 정의해서 객체 간 관계가 복잡해지지 않도록 생명주기 전 단계에서 도메인 객체의 무결성을 유지할 수 있게 해주는 Aggregate을 정의해야 합니다.
Aggregate은 업무상 관련 있는 객체들을 모아 경계를 명확히 정의하여 객체 간 관계를 복잡하지 않게 합니다. 생명주기 상의 전 단계에서 도메인 객체의 무결성을 유지할 수 있게 해주는 패턴입니다. 한마디로 표현하면, 데이터 변경의 단위로 다루는 연관된 객체의 묶음입니다.
Aggregate은 1개 이상의 Entity로 구성됩니다. 그 중 한 Entity는 Aggregate Root로 정의하며 구성에는 값 객체를 포함합니다. 하나의 트랜잭션은 오직 하나의 Aggregate만을 수정하고 Commit한다는 원칙을 갖고 있습니다. 따라서 트랜잭션 일관성과 성공을 보장하도록 Aggregate 구성요소들을 설계합니다.
그 외에도 Aggregate을 설계할 때 고려해야 할 몇 가지 고려할 사항에 대해 있습니다. Aggregate을 설계할 때 고려할 사항 중 첫 번째는 하나의 트랜잭션에서는 하나의 Aggregate만 수정한다는 것입니다. 각 Aggregate은 일관성 있는 트랜잭션 경계를 형성합니다. 이는 트랜잭션 제어가 데이터베이스에 의해 Commit될 때, 한 Aggregate 내의 모든 구성요소들은 비즈니스 규칙을 따르면서 일관성 있게 처리된다는 것이 Aggregate의 설계 규칙입니다.
그런 이유로 Aggregate을 트랜잭션 일관성을 만드는 경계라고 부르며, 트랜잭션 일관성과 성공을 보장하도록 Aggregate 구성요소들을 설계해야 합니다.
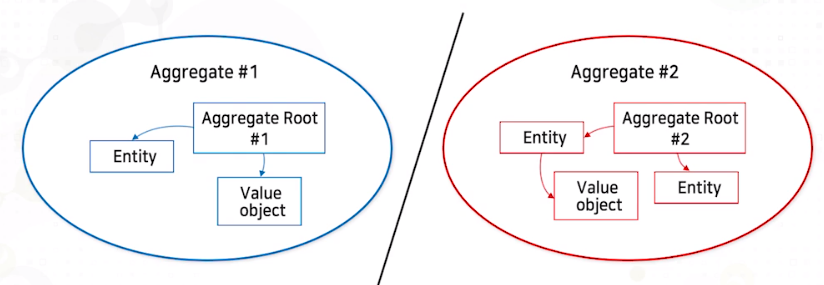
그림을 보면 2개의 Aggregate이 정의되어 있습니다. 이는 각각 단일 트랜잭션으로 Commit 되어야 합니다. 즉 Aggregate2는 Aggregate1로부터 분리된 트랜잭션으로 제어 되어야 한다는 것을 의미합니다. 두 번째는 하나의 일을 잘 수행할 수 있도록 작게 설계해야 합니다.
Aggregate은 큰 Aggregate부터 설계 했을 때보다 작게 설계할수록 성능이 좋고 확장에도 용이할 뿐 아니라 변경사항을 Commit할 때도 문제가 거의 발생되지 않습니다. Aggregate을 크게 설계하면 시간이 지날수록 하위 객체의 인스턴스의 증가가 결국 엄청난 크기로 불어날 수 있습니다. 애자일 프로젝트 관리를 예로 들면 Product는 문자 그대로 BacklogItem들 그리고 Sprint 등의 큰 모음을 담고 있습니다.
이런 모음들은 시간이 지나면서 1000개 또는 그 이상의 BacklogItem 인스턴스와 100여 개 이상의 Realese, Sprint 등으로 엄청나게 크게 불어날 수 있는 문제를 갖고 있습니다. 하지만 위와 같이 4개의 Aggregate으로 분리하게 되면 이들은 더 작은 메모리를 차지하며, 가비지 컬렉션도 빠르게 동작할 수 있습니다.
또한 각 작업이 한 명의 개발자가 관리할 수 있을 만큼 작기 때문에 수정이나 개선이 좀 더 쉬워지고 테스트 또한 쉬워질 수 있습니다. Aggregate을 설계할 때 또 새겨둬야 할 사항은 SRP 단일 책임의 원칙을 갖습니다. 만일 Aggregate이 너무 많은 일을 하고 있다는 것을 발견한다면, 이 Aggregate은 분리를 검토해야 합니다.
Aggregate을 작게 설계 하면 새로운 기능의 추가나 수정, 테스트 같은 관리도 쉬워지게 됩니다. 앞에서 큰 Aggregate을 작은 Aggregate으로 분리를 하게 되면 각 Aggregate들 간의 관계, 즉 다른 Aggregate의 수정이나 참조를 해야 하는 경우가 발생합니다. 이런 경우 한 Aggregate에서 다른 Aggregate의 참조는 식별자를 통해서만 해야 합니다. 하나의 트랜잭션 내에서 여러 개의 Aggregate이 수정되는 것을 방지할 수 있습니다. 이것이 Aggregate들을 작게 유지될 수 있게 해줍니다.
마지막은 하나의 트랜잭션에서 여러 개의 Aggregate이 갱신되어야 하는 경우입니다. 다른 Aggregate의 갱신은 결과적 일관성을 통합니다. 결과적 일관성이란 일관성을 유지시켜야 하는 데이터가 일정 기간 다른 데이터와 일치하지 않을 수도 있습니다. 하지만, 어느 시점이 되면 결국 일치하게 된다는 뜻입니다.
Aggregate이 같이 갱신되어야 하는 다른 Aggregate들과 타이트하게 물려 있게 되면 트랜잭션의 범위나 시간이 길어지게 됩니다. 이런 것들이 성능이나 오류에 의한 문제가 발생할 가능성이 높아지게 됩니다. 따라서 Aggregate의 갱신은 결과적 일관성을 통해 갱신하는 것이 바람직합니다.
주의할 사항은 모든 Aggregate이 함께 즉각적으로 갱신해야 한다고 비즈니스를 담당하는 쪽에서 강하게 주장할 수 있습니다. 실제로 프로젝트를 수행하다보면 이런 경우를 많이 만날 수 있습니다. 예를 들면 재고가 일정량 이하로 떨어지면 재고량 확보를 위해 주문을 발행합니다. 담당자는 재고량이 떨어지자마자 바로 재고 확보가 되어야 하니 재고 확보와의 즉각적인 일관성을 요구합니다.
그러나 실제로는 충분히 결과적 일관성을 통해 처리할 수 있는 문제입니다. 서로 간에 이해를 맞추는 데 많은 시간이 걸릴 수 있습니다. 따라서 결과적 일관성은 비즈니스 관점에서 고려되어야 합니다. 여러 Aggregate 간에 발생하는 갱신의 수용 가능한 소요시간을 결정하는 것이 비즈니스 관점에서 고려되어야 합니다.
애그리게잇 식별
지금까지 설명했던 Aggregate의 정의와 특징, Aggregate을 설계할 때 고려해야 할 사항들을 바탕으로 Account의 도메인 모델에서 Aggregate을 정의해 보면 Account, Address, MemberType과 MembershipLevelType을 하나의 Aggregate으로 식별할 수 있습니다. 그중 Entity로 식별했던 Account를 Aggregate으로 식별할 수 있습니다.
다른 Aggregate이 이 Account Aggregate을 갱신하기 위해서는 Aggregate인 Account를 통해서만 접근합니다. Aggregate의 Root Entity 예제에서는 Account Entity는 Aggregate 안의 다른 모든 요소를 소유하고 있다고 봅니다. 각 Aggregate은 일관성 있는 트랜잭션 경계를 형성합니다. 이것은 트랜잭션 제어가 데이터베이스에 Commit될 때 한 Aggregate 내의 모든 구성요소는 반드시 비즈니스 규칙을 따르면서 일관성 있게 처리된다는 것을 의미합니다.
'SW > 마이크로서비스' 카테고리의 다른 글
| 마이크로서비스 : 구현하기 위한 개발환경 구축 방법 : 오픈소스 종류, 활용 (0) | 2020.05.26 |
|---|---|
| 마이크로서비스 : 쇼피몽 서비스 모델링 방법 : 개념, 정의, 개요 (0) | 2020.05.25 |
| 마이크로서비스 : 엔티티, 값객체, 표준 타입 식별하기 : 정의, 개요, 방법 (0) | 2020.05.23 |
| 마이크로서비스 : 내부 설계를 위한 전술적 설계 및 주요 개념 : 정의, 개요, 설명 (0) | 2020.05.22 |
| 마이크로서비스 : 쇼핑몰 서비스 : 세번째 설계 이야기 (0) | 2020.05.15 |