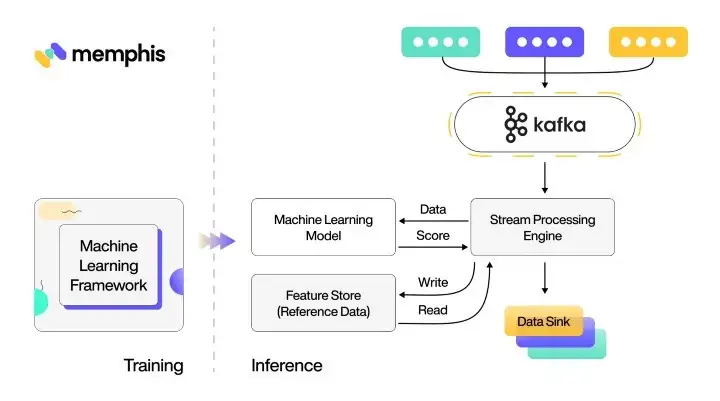
요즘 AI 배우는 거, 진짜 다르다2025년 현재, AI는 말 그대로 하루가 다르게 변하고 있어요. 그래서 예전처럼 책만 파고든다고 되는 게 아니에요. 만약 지금 제 경험과 지식을 그대로 가진 채 처음부터 다시 배운다면? 훨씬 더 감성적이고, 창의적이고, 현실적으로 접근할 것 같아요.이 글은 그냥 딱딱한 가이드가 아니에요. 함께 부딪히고, 고민하고, 진짜 '내 것'으로 만드는 여정을 같이 걸어보자는 이야기입니다. "AI, 나도 한번 해볼까?" 하고 생각한 적 있다면, 부담 갖지 말고 편하게 따라와요.AI 변화 속도에 맞춘 새로운 학습 접근이 필요함감성적이고 창의적인 방식으로 AI를 배우는 여정 제안편하게 따라오며 직접 경험하는 학습 방식 강조 Step 0: 엔지니어처럼 생각하는 법부터 배우자제일 먼저..