MSE
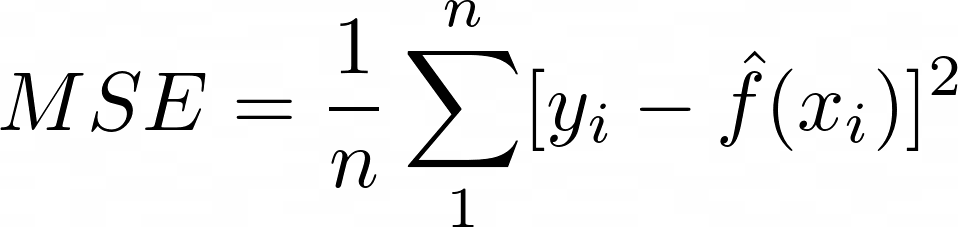
f가 제대로 추정되었는지 평가하기 위함입니다. 예측한 값이 실제 값과 유사한지 평가하는 척도가 필요합니다.
MSE ( mean squared error) 는 모형의 적합성(오류)를 평가하는 지표입니다.
MSE는 실제 종속 변수와 예측한 종속 변수간의 차이를 의미합니다. 따라서 작을수록 좋지만, 과도하게 줄이면 과적합의 오류를 범할 가능성이 있습니다. 따라서, 검증 집합의 MSE를 줄이는 방향으로 f를 추정합니다.
MAPE

mean absolute percentage error는 모형의 적합성을 평가하는 지표입니다. MAPE는 퍼센트 값을 가지며 0에 가깔우수록 회귀 모형의 성능이 좋다고 할 수 있습니다. 0% ~ 100% 사이의 값을 가져 이해하기 쉬울 수 있습니다. 성능 비교 해석이 또한 가능합니다.
Confusion Matrix (혼동 행렬)

정상과 이상을 예측하는 이진 분류에 대해 혼동 행렬을 생성할 수 있습니다. 정상과 불량을 정의하고, 맞출 경우와 틀릴 경우를 True, False라고 합니다. 이것을 위와 같이 표현할 수 있습니다.

정확도는 전체 데이터 중에서 모형으로 판단한 값이 실제 값과 부합하는 비율이라고 할 수 있습니다. 분모는 전체 데이터가 되고 분자는 모형이 실제 정상을 정상으로 그리고 실제 이상을 이상으로 옳게 분류한 데이터입니다.

정밀도는 분류 모형이 불량을 진단하기 위해 얼마나 잘 작동했는지 보여주는 지표입니다.

재현율은 데이터가 갖고 있는 불량 중 실제로 불량이라고 진단한 비율입니다.

특이도는 분류 모형의 정상을 진단하기 위해 잘 작동하는지를 보여주는 지표입니다.
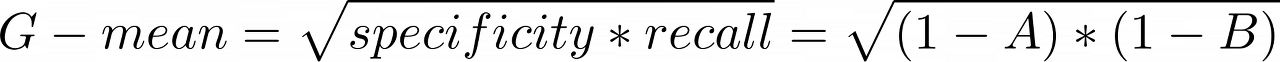

불량 데이터를 탐지하는 것이 중요합니다. 하지만, 이러한 불량 데이터는 매우 적습니다. 따라서, 정확도, 정밀도가 좋은 지표가 아닐 수 있습니다. 정확도보다는 성능이 나쁜 쪽에 더 가중치를 주는 G-mean 지표나 불량에 관여하는 지표인 정밀도와 재현율만 고려하는 F1 measure를 고려해볼 수 있는 지표라 할 수 있습니다.
분류를 위해 성능을 측정하는 여러 지표들이 있고, 개발하고 만들어가는 데이터에 특성에 따라 다양한 지표들을 활용해 개발해나가야 한다는 것을 알게 되었습니다.
'SW > 머신러닝' 카테고리의 다른 글
| 머신러닝 : 단순 선형 회귀 분석 : 잔차의 의미 : 추정 방법 (0) | 2020.01.19 |
|---|---|
| 머신러닝 : 단순 선형 회귀분석 : 개념, 기능, 방법, 개요 (0) | 2020.01.18 |
| 머신러닝 : k-Fold 교차 검증 (k-Fold Cross Validation) : 개념, 방식 (0) | 2020.01.15 |
| 머신러닝 : 데이터 분할 : 방법, 방식, 절차 (0) | 2020.01.14 |
| 머신러닝 : 모형의 적합성 : 평가 방법 (0) | 2020.01.13 |