http://archive.ics.uci.edu/ml/datasets/Adult
UCI Machine Learning Repository: Adult Data Set
Adult Data Set Download: Data Folder, Data Set Description Abstract: Predict whether income exceeds $50K/yr based on census data. Also known as "Census Income" dataset. Data Set Characteristics: Multivariate Number of Instances: 48842 Area: Social Attrib
archive.ics.uci.edu
실습에 필요한 데이터는 위 사이트에서 받아 올 수 있습니다. 제일 용량이 큰 데이터를 활용합니다.
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from keras.layers import *
from keras.models import *
from keras.utils import *
from sklearn.preprocessing import *
import seaborn as sns
우선 필요한 라이브러리들을 임포트합니다.
colNames = ['age', 'work', 'fnlwgt', 'education', 'education-num', 'mari', 'occupation', 'relationship', 'race', 'sex', 'cg', 'c', 'hw', 'na', '50k']
df = pd.read_csv('adult.data',
names=colNames,
index_col=False)
df.head()

해당 데이터를 읽은 뒤, 출력한 결과는 위와 같습니다.
df.describe()

읽어온 데이터들은 위와 같습니다.
df.count()

데이터는 약 3만개 정도 되었습니다.
sns.heatmap(df.corr(), annot=True, cmap='summer_r', linewidths=0.2)
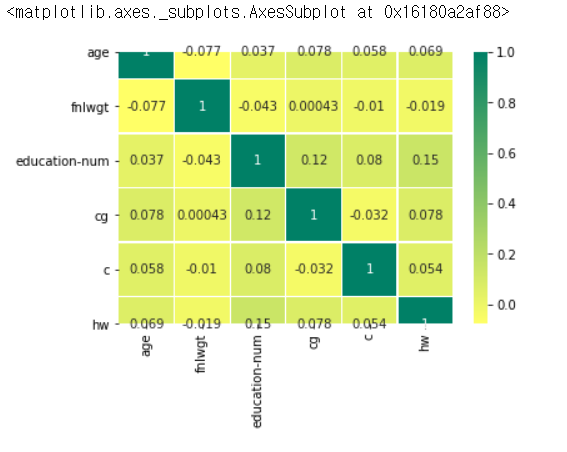
각 컬럼마다 상관계수를 구한 값은 위와 같습니다.
plt.figure(figsize=(7,7))
sns.violinplot('race', 'age', hue='50k', data=df, split=True)

인종에 따른, 급여의 차이는 위와 같이 표현할 수 있습니다.
Y = df['50k'].values.tolist()
Y = [1 if i == ' <=50K' else 0 for i in Y]
Y = to_categorical(Y)
이제 출력 데이터를 준비해보겠습니다.
X = df.drop(['age', 'fnlwgt', 'education-num', 'cg', 'c', 'hw', '50k'], axis=1)
X = pd.get_dummies(X, drop_first=True)
X = pd.concat([X, df[['age', 'fnlwgt', 'education-num', 'cg', 'c', 'hw']]], axis=1)
scaler = MinMaxScaler()
X[['age', 'fnlwgt', 'education-num', 'cg', 'c', 'hw']] = scaler.fit_transform(X[['age', 'fnlwgt', 'education-num', 'cg', 'c', 'hw']])
받은 데이터를 입력데이터로 활용합니다. 문자열 데이터는 위와 같이 전처리하여 활용합니다.
x_train = X[:-1000]
x_test = X[-1000:]
y_train = Y[:-1000]
y_test = Y[-1000:]
훈련데이터와 테스트 데이터를 나누어 줍니다.
model = Sequential()
model.add(Dense(1024, activation='relu', input_shape=(100,)))
model.add(Dense(512, activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(2, activation='softmax'))
model.summary()
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
hist = model.fit(x_train, y_train, epochs=5, validation_split=0.2)
"""
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_29 (Dense) (None, 1024) 103424
_________________________________________________________________
dense_30 (Dense) (None, 512) 524800
_________________________________________________________________
dense_31 (Dense) (None, 128) 65664
_________________________________________________________________
dense_32 (Dense) (None, 2) 258
=================================================================
Total params: 694,146
Trainable params: 694,146
Non-trainable params: 0
_________________________________________________________________
Train on 25248 samples, validate on 6313 samples
Epoch 1/5
25248/25248 [==============================] - 4s 154us/step - loss: 0.4221 - acc: 0.7994 - val_loss: 0.3780 - val_acc: 0.8288
Epoch 2/5
25248/25248 [==============================] - 4s 139us/step - loss: 0.3644 - acc: 0.8307 - val_loss: 0.3589 - val_acc: 0.8323
Epoch 3/5
25248/25248 [==============================] - 3s 135us/step - loss: 0.3525 - acc: 0.8360 - val_loss: 0.3522 - val_acc: 0.8383
Epoch 4/5
25248/25248 [==============================] - 3s 131us/step - loss: 0.3458 - acc: 0.8383 - val_loss: 0.3435 - val_acc: 0.8378
Epoch 5/5
25248/25248 [==============================] - 3s 131us/step - loss: 0.3406 - acc: 0.8410 - val_loss: 0.3472 - val_acc: 0.8370
"""
이제 훈련을 진행하면 위와 같은 결과를 얻을 수 있습니다.
print(hist.history)
plt.figure(figsize=(10,10))
plt.subplot(1,2,1)
plt.plot(hist.history['acc'], color='r')
plt.plot(hist.history['val_acc'], color='b')
plt.title('acc')
plt.subplot(1,2,2)
plt.plot(hist.history['loss'], color='r')
plt.plot(hist.history['val_loss'], color='b')
"""
{'val_loss': [0.37801867696084407, 0.3588594136998334, 0.352239245240518, 0.34345897974594825, 0.3471839559374682], 'val_acc': [0.8287660383524805, 0.8322509108378282, 0.8382702360397923, 0.8377950261554268, 0.8370030096814841], 'loss': [0.422121320047306, 0.36436177946919873, 0.3524622400450616, 0.3458335296509384, 0.340608370375875], 'acc': [0.7994296577946768, 0.8307192648922687, 0.8359870088719898, 0.8382842205323194, 0.8410171102661597]}
"""

훈련 진행 그래프를 다음과 같이 확인할 수 있습니다.
score = model.evaluate(x_test, y_test)
pred = model.predict(x_test)
print(score)
print(pred[:10])
print(Y[:10])
"""
1000/1000 [==============================] - 0s 45us/step
[0.3620321855545044, 0.821]
[[0.81822085 0.18177913]
[0.03373788 0.96626216]
[0.34499687 0.65500313]
[0.02908773 0.9709122 ]
[0.7562098 0.24379018]
[0.01228678 0.9877132 ]
[0.00909141 0.99090856]
[0.0046048 0.9953951 ]
[0.2967174 0.70328254]
[0.01453881 0.9854612 ]]
[[0. 1.]
[0. 1.]
[0. 1.]
[0. 1.]
[0. 1.]
[0. 1.]
[0. 1.]
[1. 0.]
[1. 0.]
[1. 0.]]
"""
인풋 데이터를 통해, 이 사람의 수입이 50k가 넘는지, 안넘는 지에 대한 예습을 진행하였습니다. 간단한 모델을 가지고 진행한 결과 약 80프로의 정확도를 가지는 것을 확인할 수 있었습니다.
이처럼, 사람의 신상 정보들을 추론해, 사람들의 숨겨진 정보를 예측하고, 서비스할 수 있다는 것을 어느정도는 보여준 사례라고 생각됩니다.
다양한 모델을 좀 더 상세하게 쓴다면, 더욱 높은 정확도로 예측할 수 있을 것이라 생각됩니다.
'SW > Python' 카테고리의 다른 글
| Python : Keras : 콘크리트 강도 분류 예측하기 : 예제, 방법, 컨셉 (0) | 2020.02.07 |
|---|---|
| Python : Keras : iris 품종 예측하기 : 예제, 구현, 방법 (0) | 2020.02.06 |
| pywinauto : 원격 접속 에러 : 원인, 방법 (0) | 2020.02.02 |
| python : 파일 또는 셸을 통해 스크립트를 실행하는 방법 , 종류 (0) | 2019.11.29 |
| 왜 파이썬은 강력한 언어일까? (0) | 2019.11.06 |