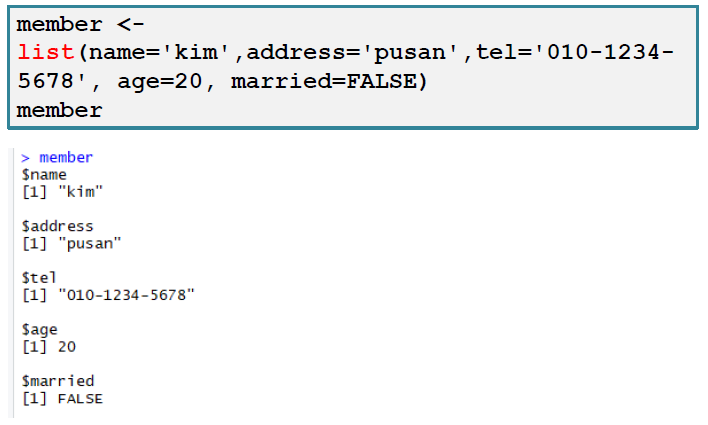
버블 차트(bubble chart)예전부터 저의 포스팅을 보신 분이라면 산점도를 이해하고 계실 것입니다. 산점도는 두 가지의 변수간의 상관 관계를 나타냅니다. 버블 차트는 산점도의 한 종류입니다. 제3의 변수를 크기에 따라 버블로 표현하는 차트입니다. 아래 그림은 버블 차트의 한 종류입니다. 느낌이 오시나요? 버블차트를 이용하시려면 패키지를 설치하셔야 합니다. 패키지 명은 MASS입니다. 관련 패키지를 설치해주세요. 만약 패키지 설치하는 방법을 모르시는 분은 제가 이전에 포스팅한 패키지 설치 방법을 참조하시면 됩니다. 이번에 실습에 사용할 데이터셋은 UScrime입니다. 딱봐도 미국 범죄와 관련된 내용이겠죠? 인구수, 실업률, 범죄율 등의 데이터가 저장되어 있습니다. 실습 예제 library(MASS) ..