먼저 Reinforcement Learning (RL)과 Gradient Boosting이 뭔지 간단하게 설명해 볼게요. 그리고 이번 논문에서 제안한 프레임워크가 실제로 어떻게 작동하는지 이야기하고, 그 알고리즘의 깊은 내용도 다뤄보겠습니다. 마지막으로 실험 결과를 통해 이 방법이 얼마나 효과적이었는지, 또 어떤 점에서 힘들었는지까지 함께 살펴볼 거예요. 솔직히 이 과정에서 약간 어려운 부분도 있었지만, 그만큼 배운 것도 많았어요.

Reinforcement Learning (RL) 기본 개념
- RL이란 에이전트가 환경에서 행동을 통해 학습하는 방식
- Deep RL은 Neural Network를 사용해 에이전트를 더 똑똑하게 만드는 것
자, 그럼 Reinforcement Learning, 줄여서 RL에 대해 간단히 얘기해볼게요. RL은 쉽게 말해 에이전트가 특정 상황에서 행동을 하고, 그 행동이 환경에 어떤 영향을 미치는지를 학습하는 방식입니다. 예를 들어 로봇 팔을 떠올려 보세요. 에이전트는 이 로봇 팔을 제어하는 역할을 하고, 환경은 물건을 집는 작업일 수 있겠죠. 팔은 왼쪽, 오른쪽, 위, 아래 등 어디로 움직일지 결정해요. 만약 물건을 잘 집으면 보상을 받고, 반대로 멀어지면 페널티를 받는 거예요. 결국 에이전트는 어떻게든 더 나은 행동을 하려고 배우는 거죠. 이 과정이 사실 꽤 재미있어요.
그리고 Deep RL이라는 개념도 있는데요, 이건 에이전트를 Neural Network, 즉 신경망을 이용해 훨씬 더 똑똑하게 만드는 걸 의미해요. 복잡한 데이터를 바탕으로 더 나은 행동을 할 수 있게 하려는 거죠. 이런 상황에서 어떤 행동을 해야 하는지 결정하는 지도를 "policy"라고 불러요. Neural Network는 이 policy를 학습해서 좀 더 복잡한 문제도 풀어내게 돕는 거예요.
Policy Optimization과 Gradient 기반 접근법
- policy의 weights를 최적화해 보상을 최대화 과정
- Gradient 기반 방법을 사용해 최적 상태를 찾음
- Actor-Critic 구조를 통해 정책을 학습하고 개선하는 방식
이제 policy 최적화에 대해 이야기해 볼게요. policy의 "weights"를 조정해 보상을 최대화하는 것이 목표인데, 이 과정에서 Gradient 기반 방법이 사용됩니다. 말이 어렵게 들리지만, 간단히 말해 최적의 상태를 찾기 위해 기울기를 이용하는 거예요. 이건 전통적인 RL 방식에서 많이 사용되는 Actor-Critic 구조와 비슷합니다. Actor는 행동을 하고, Critic은 그 행동이 좋았는지 나빴는지를 평가하면서 배우는 거죠. 마치 선생님이 학생에게 피드백을 주며 더 나은 답을 찾도록 도와주는 것과 비슷해요.
여기서 중요한 건 "TD Error (Temporal Difference Error)"를 최소화하는 거예요. TD Error는 우리가 기대했던 결과와 실제 결과의 차이를 측정하는데, 이걸 줄여야 가치 함수가 정확히 업데이트될 수 있어요. 시간이 지남에 따라 이 가치 함수가 개선되면서 Actor는 더 나은 선택을 하게 되는 거죠. 마치 전문가의 조언을 받으며 점점 더 좋은 답을 찾아가는 학생 같은 느낌이에요.
Proximal Policy Optimization (PPO)
- PPO는 학습을 안정적으로 만드는 알고리즘
- "clipping" 기법을 사용해 급격한 변화 방지
- 안전하면서도 성능을 극대화하는 정책 업데이트 방식
이제 Proximal Policy Optimization, 줄여서 PPO에 대해 이야기해 볼게요. PPO는 학습을 더 안정적으로 만들기 위한 알고리즘이에요. 갑자기 언덕을 오르는 장면이 떠오르는데요, 대각선으로 곧장 올라가는 게 가장 빠를 수도 있지만, 잘못하면 크게 굴러 떨어질 위험이 있잖아요. PPO는 "clipping"이라는 기술을 사용해서 policy가 너무 급격하게 변하지 않도록 해줘요. 한마디로 천천히, 그러나 확실하게 정상에 도달하도록 돕는 거죠.
PPO의 핵심은 안전하게 정책을 업데이트하면서도 성능을 극대화하는 거예요. 마치 신중한 여행자가 무모한 모험을 피하고 안전한 길을 택해 정상에 오르는 것과 비슷하다고 보면 돼요. 학습 과정에서 갑작스러운 변화는 오히려 위험할 수 있으니까요.
Off-Policy Learning과 W-Regression
- Off-Policy 학습은 에이전트가 직접 수집한 데이터가 아니더라도 학습
- Advantage Weighted Regression (AWR)에서 가치 함수와 정책 업데이트의 최적화
- 다양한 정책을 시도하며 최적의 행동 학습
이번에는 조금 다른 접근법인 W-Regression에 대해 얘기해 볼게요. 이건 논문에서 다룬 마지막 RL 접근법인데요, On-Policy 알고리즘과 달리 Off-Policy 방식을 사용합니다. 쉽게 말해, 에이전트가 직접 수집한 데이터가 아니더라도 학습할 수 있는 거예요. 마치 다른 사람의 경험을 듣고 배우는 것처럼요. 이렇게 다양한 정책들을 시도해 보면서 최적의 행동 방침을 찾으려고 하는 거예요. 그리고 "replay buffer"라는 것을 사용해 에이전트가 과거의 경험을 반복해서 학습하고 더 나은 결정을 내리도록 도와줍니다.
Advantage Weighted Regression (AWR) 방법에서는 두 가지 주요 목표가 있습니다. 첫 번째는 가치 함수를 최적화하는 것이고, 두 번째는 정책을 업데이트하는 거예요. 가치 함수는 에이전트가 실수를 줄이는 데 도움을 주고, 정책 업데이트는 좋은 행동을 더 자주 하도록 만드는 데 초점을 맞춥니다. 이 두 가지가 잘 맞아떨어져야 에이전트가 진짜로 똑똑해질 수 있죠.
Gradient Boosting 소개
- 여러 Decision Trees를 결합해 예측 능력을 향상시키는 방법
- Decision Tree를 RL 프레임워크에 적용해최적화
- Neural Network 대신 Decision Tree를 사용하는 점이 차별
이제 Gradient Boosting에 대해 이야기해볼까요? Gradient Boosting은 여러 Decision Trees를 결합해서 예측 능력을 점점 더 높여주는 방법입니다. 이번 논문에서는 Decision Tree들을 RL 프레임워크에 적용하고 Gradient Boosting을 통해 최적화하고 있어요.
목표는 손실을 줄이기 위해 반복적으로 매개변수를 조정하고, Decision Tree를 이용해 RL 에이전트가 최적 경로를 찾도록 하는 겁니다. 간단히 말해서, 첫 번째로 개선 방향을 찾기 위해 Gradient를 계산하고, 두 번째로 그 Gradient를 활용해 Decision Tree를 업데이트하여 최적의 솔루션에 도달하는 과정이에요.
이 프레임워크의 차별점은 Neural Network 대신 Decision Tree를 사용한다는 것인데요, 각 반복에서 에이전트가 조금씩 더 나은 결정을 내릴 수 있도록 설계되어 있어요. 기존의 방식과는 또 다른 흥미로운 접근법이에요.
구현 세부 사항
- 매개변수, buffer 크기, iteration 횟수 설정 후 에이전트가 학습
- gradient 계산과 policy 업데이트를 반복해 에이전트가 최적의 policy에 도달
- 반복적으로 Decision Tree를 활용해 정책 강화
구현 과정도 조금 더 이야기해 볼까요? 먼저 매개변수, buffer 크기, iteration 횟수를 설정하는 것으로 시작해요. 그다음에 에이전트는 현재 policy를 바탕으로 환경과 상호작용하고, 보상을 저장한 뒤 계산된 gradient를 사용해 업데이트를 진행하는 'trajectory collection' 단계를 거칩니다. 쉽게 말해, 샘플링하고, gradient를 계산하고, policy와 가치 함수를 업데이트하는 일을 반복하는 거예요.
최종 목표는 이 Decision Tree들이 각 반복마다 더 스마트해져서 에이전트가 최적의 policy를 찾을 수 있게 돕는 거예요. 마치 이 Tree들이 policy의 행동을 지시하는 백본 같은 역할을 한다고 보면 돼요. 반복을 거듭하면서 에이전트는 점점 더 정확해지고, 보상을 극대화하는 행동을 하게 되는 거죠.
실험 분석
- RL 작업 처리, Neural Network 기반 알고리즘과의 비교, 구조화된 데이터 환경에서의 성능 등 다섯 가지 질문에 대한 실험
- CartPole, Lunar Lander, MountainCar 등 전통적 환경에서의 성과
- 고차원 환경에서는 좋은 성과를 보였지만, 비구조적 환경에서는 어려움을 겪음
이번 실험에서는 다섯 가지 중요한 질문에 답하려고 했어요:
- 이 방법이 고차원적이고 복잡한 RL 작업을 처리할 수 있는가?
- A2C, PPO, AWR 같은 Neural Network 기반 RL 알고리즘과 비교했을 때 성능은 어떠한가?
- 구조화된 범주형 데이터 환경에서 성능은 어떤가?
- XGBoost나 CatBoost 같은 기존 Machine Learning 방법과 비교했을 때 RL 작업 해결 능력은 어떤가?
- 가치와 policy Decision Tree를 공유할 때 메모리 효율성은 어떤가?
먼저, CartPole, Lunar Lander, MountainCar 같은 전통적인 RL 벤치마크 환경에서 테스트를 진행했어요. 결과는 혼재되어 있었는데, 어떤 작업에서는 제안된 방법이 뛰어난 성과를 보였고, 다른 작업에서는 Neural Network 기반 방법보다 부족했어요. 예를 들어, CartPole 같은 구조화된 환경에서는 좋은 성과를 냈지만, pendulum swing 같은 비구조적인 환경에서는 어려움을 겪었죠.
그리고 Google Research Football Academy처럼 고차원적인 환경에서는 꽤 좋은 성능을 보였습니다. 목표가 명확한 구조화된 작업(예: 공을 패스하거나 골을 넣는 것)에서는 이 방법이 돋보였지만, Atari 기반의 비구조적인 게임에서는 복잡성 때문에 어려움을 겪었어요. 특히 Alien, Breakout, Crawlers 같은 Atari RAM 기반 작업에서는 Neural Network 기반 방법이 더 좋은 성과를 보였어요. 이렇게 명확한 행동-보상 구조가 없는 유동적이고 역동적인 환경에서는 Decision Tree가 어려워하는 게 보였어요.
하지만 MiniGrid 같은 구조화된 범주형 데이터 환경에서는 다시 좋은 성과를 보였고, 정답이 명확한 단순한 작업을 잘 처리하는 모습을 보여줬어요.
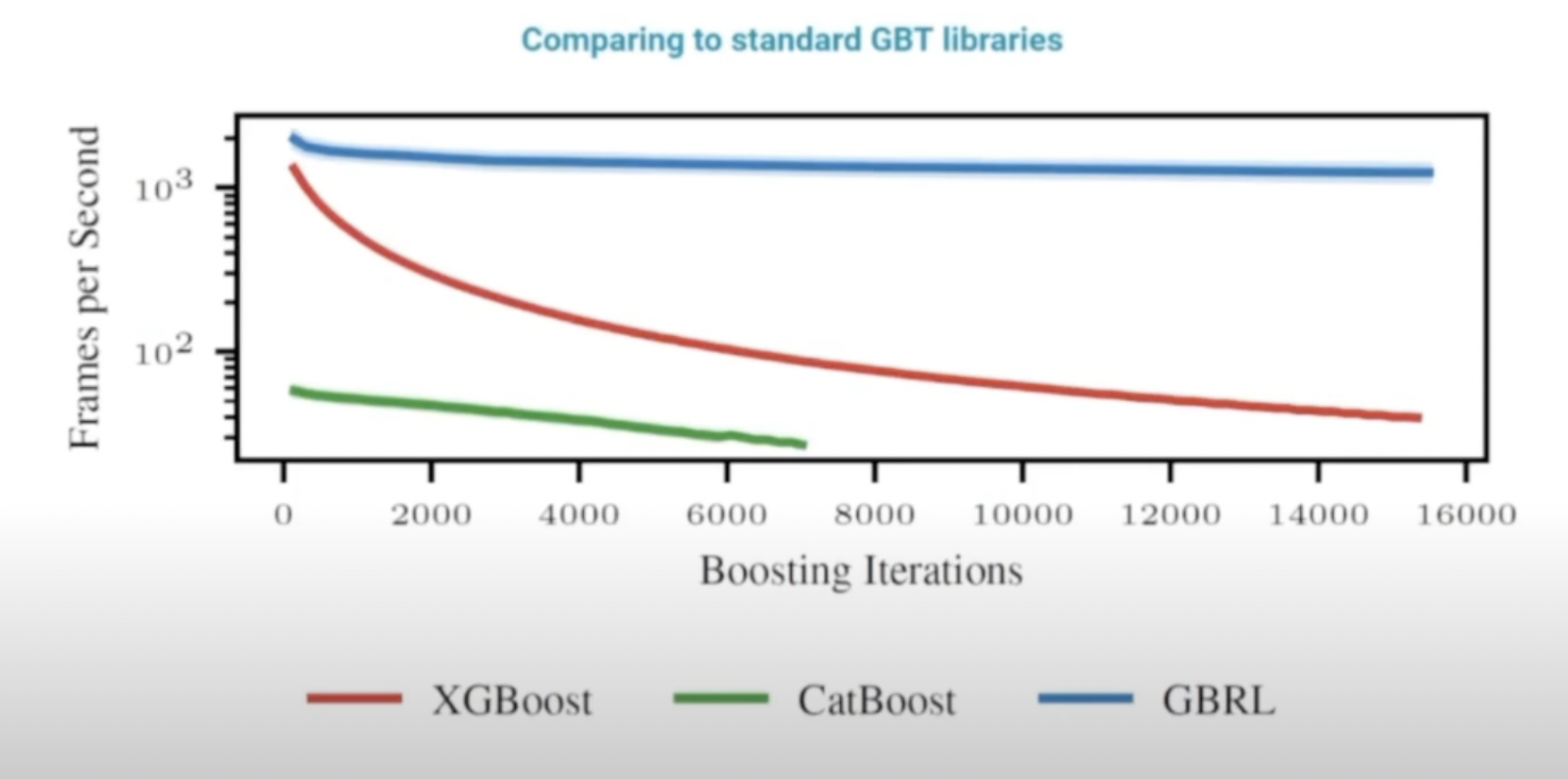
기존 Machine Learning 방법과의 비교
- XGBoost, CatBoost와 비교해 RL 환경에서 더 나은 성과를 보임.
- Decision Tree 공유 구조로 인해 GPU 메모리 효율성 향상.
마지막으로, XGBoost와 CatBoost와 비교했을 때, 이번에 제안된 RL 접근법이 더 나은 성과를 냈다는 점을 알 수 있었습니다. 기존의 Gradient Boosting 방법들이 동적인 RL 환경에서는 약간의 한계를 보인다는 걸 보여줬어요. 게다가 Decision Tree를 공유하는 구조가 메모리 효율적이어서, 가치와 policy Tree를 공유할 때 GPU 메모리 사용량도 많이 줄일 수 있었어요.
결론
- Decision Tree 기반 RL 접근법은 구조화된 작업에서는 잘 작동하지만, 비구조적인 환경에서는 어려움이 있음.
- CUDA 지원 덕분에 계산 효율성이 향상되었고, 향후 연구에 긍정적인 영향을 미칠 가능성.
결론적으로 이 Decision Tree 기반 RL 접근법은 구조화된 작업에서는 잘 작동하지만, 비구조적이거나 덜 명확한 환경에서는 여전히 어려움을 겪습니다. 하지만 GPU 메모리 사용 효율성과 구조화된 환경에서의 성능은 꽤 긍정적이에요. 단, Tree가 깊어질수록 더 많은 자원이 필요하기 때문에 Off-Policy 환경에서는 도전이 될 수 있습니다.
한 가지 긍정적인 점은, 엔비디아에서 제공하는 CUDA 지원 덕분에 계산 효율성이 크게 향상되었다는 점입니다. 이는 향후 연구에 좋은 기반이 될 수 있어요. Stable-baselines3의 Critic 공유 기능과 핵심 알고리즘도 온라인에서 사용할 수 있기 때문에 다른 연구자들도 쉽게 실험할 수 있을 거예요.
'SW > 강화학습' 카테고리의 다른 글
| Double Gumbel Q-Learning: 강화 학습의 새로운 접근법 (0) | 2025.02.05 |
|---|---|
| 01. 강화 학습 개요 (0) | 2021.05.25 |
| 강화학습 : GYM과 Stable Baselines를 사용하는 이유와 배경 (0) | 2020.05.22 |