
이 섹션에서는 최적화에 대한 섹션으로, 모델 매개 변수에 모두 사용하는 알고리즘을 참조합니다. 지금까지 기울기 하강 만 보았으므로 이제 개선된 알고리즘으로 이어지는 사항에 대해 논의할 때입니다.
대부분 이론적인 관점에서 볼 때 가치가 있지만 실제 실행에서는 느립니다. 따라서 이러한 상황을 극복해야할 단계가 있습니다 .
가중치를 업데이트 하기전에 전체 훈련 세트를 통한 각 업데이트는 변화가 매우 작습니다. 이것은 학습 속도의 작은 값에 의해 구동되는 기울기 하강의 전체 개념 때문입니다. 기억하는 것처럼 위험에 처할 때 너무 높은 값을 사용할 수 없었습니다. 따라서 매우 작은 학습 속도를 사용하여 많은 포인트에 걸쳐 많은 에포크를 가지고 있습니다. 이것은 느립니다. 기본적으로 그라디언트를 항해합니다.
SGD 또는 확률적 그라디언트 디센트라고 하는 유사한 알고리즘으로, 똑같은 방식으로 작동하지만 에포크 당 한번 가중치를 업데이트하는 대신 단일 에포크 내부에서 실시간으로 업데이트합니다. 확률적 그라디언트 디센트는 배치의 개념과 밀접한 관련이 있습니다. 배치는 데이터를 여러 배치로 나누는 프로세스이며 많은 배치를 의미합니다. 모든 에포크 대신 배치마다 가중치를 업데이트합니다.
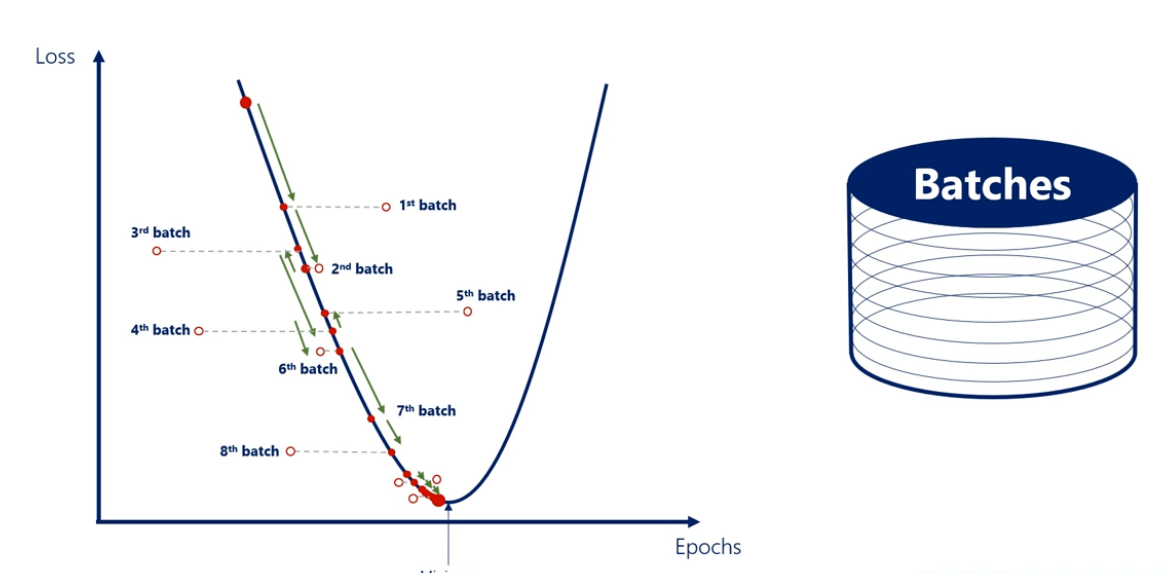
10000 개의 훈련 포인트가 있다고 가정해 봅시다. 1000의 배치 크기에 에포크당 10 개의 배치가 있습니다. 따라서 훈련 데이터 세트에 대한 전체 반복마다 가중치를 10회 업데이트합니다. 이는 새로운 방법이 아니며, 그래디언트 디센트와 동일합니다. SGD는 비용이 많이 듭니다. 약간의 근사치이므로 약간의 정확도는 떨어지지만 그만한 가치는 있습니다.
업계의 거의 모든 사람들이 사용한다는 사실이 확인됩니다. 왜 이렇게 알고리즘의 속도를 대폭 향상 시키는가에 대해 이야기 할 가치가 있습니다. 몇 가지 이유가 있지만 가장 좋은 방법 중 하나는 훈련 세트를 배치로 나누는 하드웨어와 관련이 있습니다.
연산 장치를 통해 여러 배치를 동시에 학습 할 수 있습니다. 이것은 놀라운 속도 향상을 제공하여 실무자들이 의존하는 이유입니다. 다른 이유는 모든 입력 후에 업데이트 할 때 실제로 확률적 그라디언트 디센트는 배치입니다. 기술적으로 미니 배치라고합니다.
그라디언트 디센트 실무자들은 미니 배치 GD를 확률적 하강 디스트릭트라고 부르는 경우가 많지만, 시작 부분에서 논의한 평면 그래디언트 디센트는 단일 배치이므로 배치 Gd라고합니다.
'SW > 딥러닝' 카테고리의 다른 글
| 32. 딥러닝 : 모멘텀 (Momentum) : 개념, 원리, 필요 이유 (1) | 2020.03.26 |
|---|---|
| 31. 딥러닝 : 경사 하강 함정 (gradient descent pitfalls) : 원인, 이유, 배경 (0) | 2020.03.25 |
| 29. 딥러닝 : Xavier Initialization (변수 초기화 방법 ) : 개념, 방식, 원리, 적용 (0) | 2020.03.23 |
| 28. 딥러닝 : 단순 초기화의 타입 : 초기화 유형, 방법, 개념, 유념 (0) | 2020.03.22 |
| 27. 딥러닝 : 오버피팅(과적합) : 훈련 멈추는 시점, 팁, 개념, 종류 (0) | 2020.03.14 |