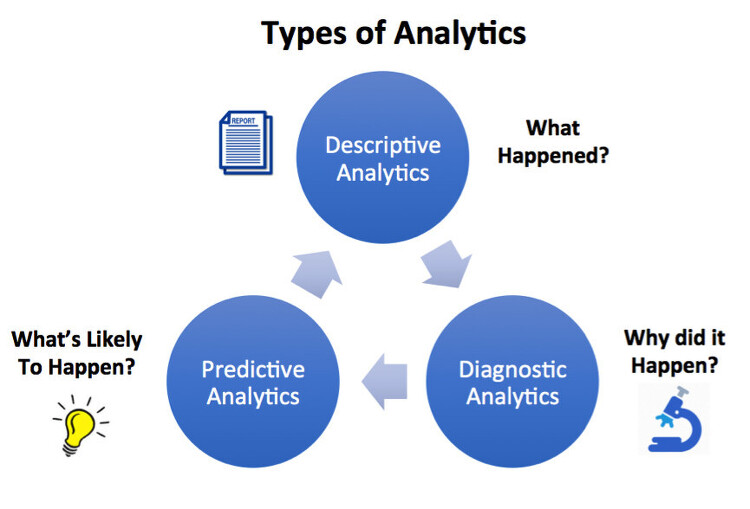
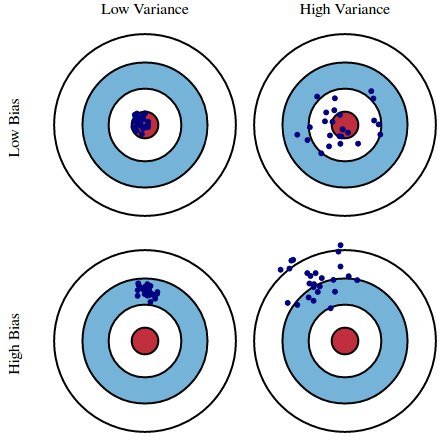
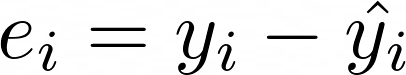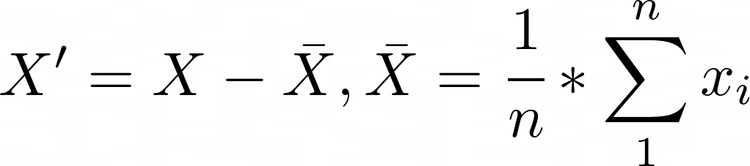분석이 ML과 어떻게 관련이 있는지 설명하겠습니다. 머신러닝과 관련된 몇 가지 말도 안 되는 말들을 해독하고 ML의 프로세스와 유형을 설명하겠습니다. 분석이 머신러닝과 어떻게 관련이 있는지 설명하겠습니다. ML에 관한 몇 가지 말도 안 되는 말들을 해독하고, 기계 학습의 과정과 유형을 설명하려고 노력할 것입니다. 마지막으로, 다음 단계의 인공지능 - 딥 러닝을 설명하는 몇 개의 비디오를 공유할 것입니다. 인공지능 전문가가 아니더라도 걱정하지 마십시오. 선형 회귀 및 K-평균 클러스터링에 대해서는 다시 언급하지 않겠습니다. 이것은 쉬운 영어로 된 기사입니다. 분석 및 기계 학습 빅 데이터는 SQL 쿼리와 테라바이트급 데이터의 전부라고 생각해도 무방하겠지만, 진정한 목적은 통찰력을 확보하여 데이터에서 가치를..