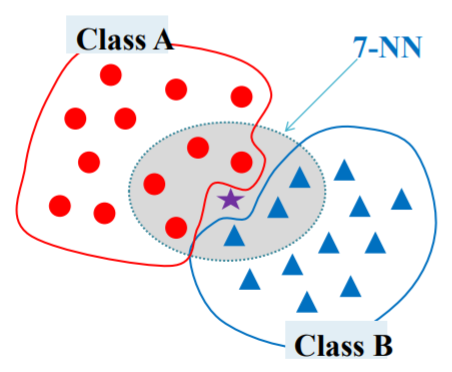
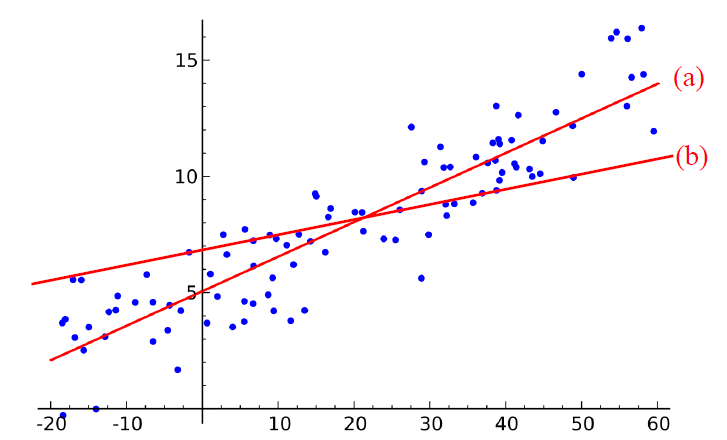
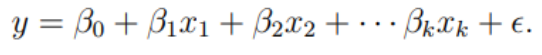K-fold Cross Validation 오직 하나의 분류 실험만으로 충분할까요? Test 데이터셋을 다르게 만들면 accuracy가 달라질 것입니다. 따라서 Test 데이터셋이 어떻게 구성되었는가에 따라 accuracy가 원래 성능보다 높거나 낮게 나올 수도 있습니다. 그렇다면 어떻게 해야 분류 모델 또는 분류 알고리즘의 성능을 보다 정확히 알 수 있을까요? 데이터셋의 K-fold partition을 생성합니다. 각각의 k의 실험에서 훈련을 위해 k-1 부분을 테스팅용으로 남기는 방식으로 진행합니다. 보통 k는 10으로 많이 사용합니다. 델(or 알고리즘)의 정확도는 각 fold의 정확도들의 평균으로 계산합니다. 평균을 구하는 식 3-fold cross validation모든 클래스에서 균등한 비율(..