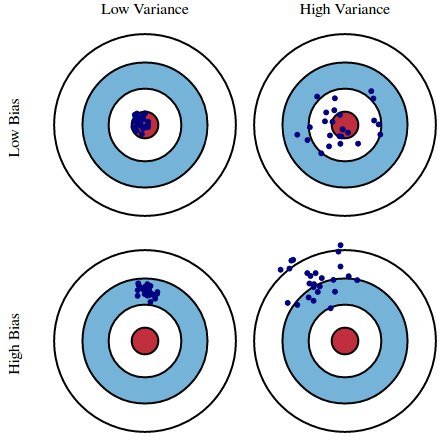
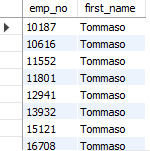
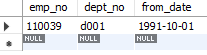
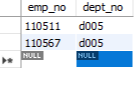
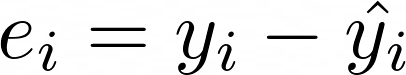데이터 저장하기 insert 문을 활용하면 데이터를 저장할 수 있습니다. 이 때, 로우 단위로 저장됩니다. insert into 테이블명 (컬럼명) values (값) insert into 테이블명 values (값) 컬럼에 저장될 값을 지정하지 않으면 null이 저장됩니다. 일반적으로 실수 하지 않도록, 컬럼명을 지정하고 값을 저장하는 것을 추천합니다. 데이터 수정하기 update 문을 활용하면 데이터를 수정할 수 있습니다. update 테이블명 set 컬럼명=값, 컬럼명=값 where 조건식 데이터 삭제하기 delete 문을 활용하면 데이터를 삭제할 수 있습니다. delete from 테이블명 where 조건식 만약 조건식이 없으면 해당 로우가 모두 삭제됩니다.