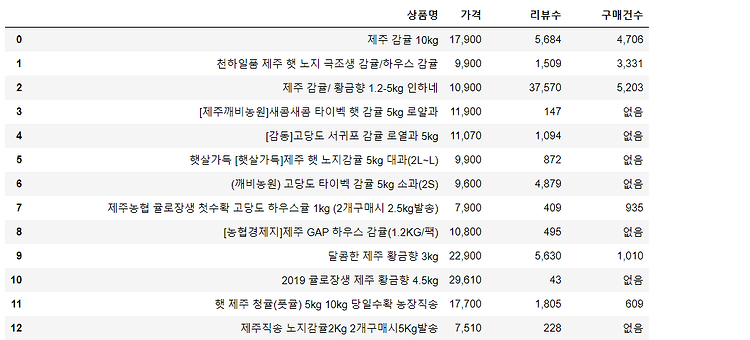
사람들이 혈액 및 소변 검사를 받도록 안내할 수 있는 세상을 상상해 보았습니다. 이 모든 것이 건강 관리 기록, 게놈 데이터, 의료 이미지, 심박수를 모니터링하는 과거 데이터, 혈압을 분석하는 AI 시스템에 의해 결정될 수 있습니다. 그리고 이 시스템에 의해 권장된 사항은 수백만 명의 환자를 관찰한 수 천 개의 훈련 사례가 있는 수백만 개의 세포 생물학 데이터 세트를 기반으로 합니다. 혈액 검사에서 신체 변화 또는 신체 유전자에서 발현된 모든RNA 분자의 합계가 감지될 수 있습니다. 소변 검사는 또한 대사 산물의 변경 또는 모든 대사 산물의 총합 (대사 기능에 필요한 물질)을 감지하여 신경 근성 퇴행성 장애가 있음을 시사합니다. 태어날 때 자궁에서 관련 병원성 변형체를 조작할 수 있었기 때문에, AI 시..