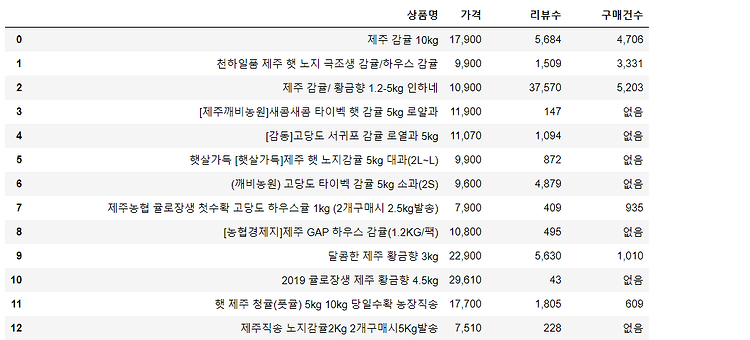
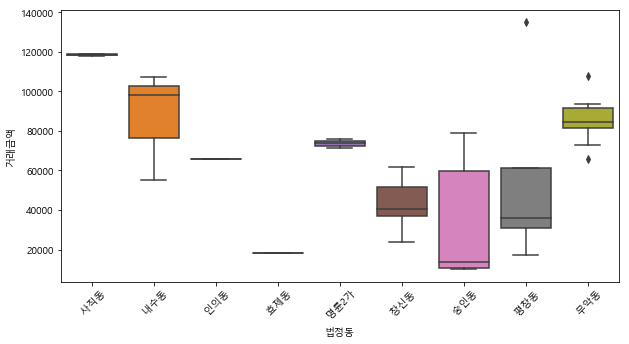
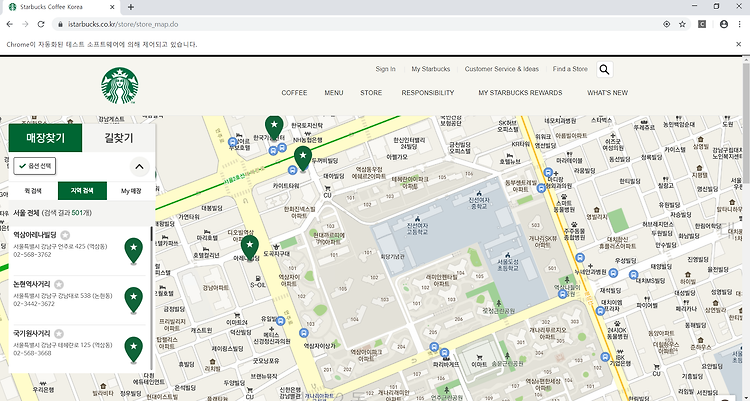
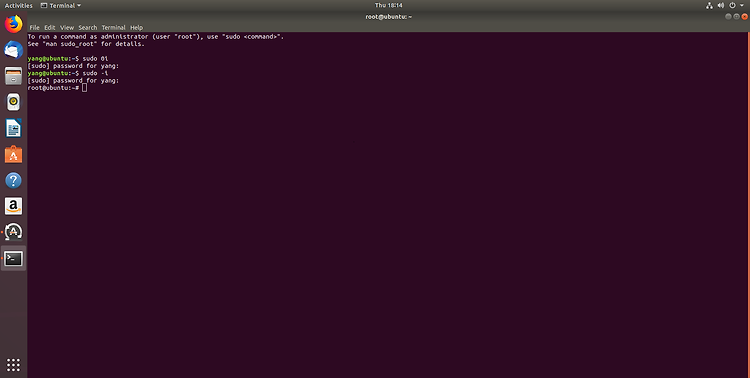
Codility는 코더의 스킬 셋을 테스트하기 위한 플랫폼입니다. 테스트를 통해 채용 프로세스 중에 코더에게 기술 화면을 제공 할 수 있습니다. 아마도 가장 큰 장점은 테스트가 자동으로 제공되고 점수가 매겨져 기술이 아닌 채용 담당자가 전 세계의 후보자를 관리 할 수 있다는 것입니다. 알고리즘 테스트에 관한 것은 매우 좁은 기술 세트를 테스트한다는 것입니다. 대부분의 경우, 소프트웨어 개발자는 알고리즘을 작성하는 데 많은 시간을 소비하지 않습니다. 기존 라이브러리의 알고리즘을 활용하면서 더 높은 수준의 문제에 중점을 둡니다. 이로 인해 개발 프로세스는 더 빠르고 버그가 덜 발생합니다. 따라서 코딜리티 테스트는 응시자가 응용 프로그램의 기본 빌드 블록을 구축 할 수 있는지 확인하는 데 유용합니다. 문제..