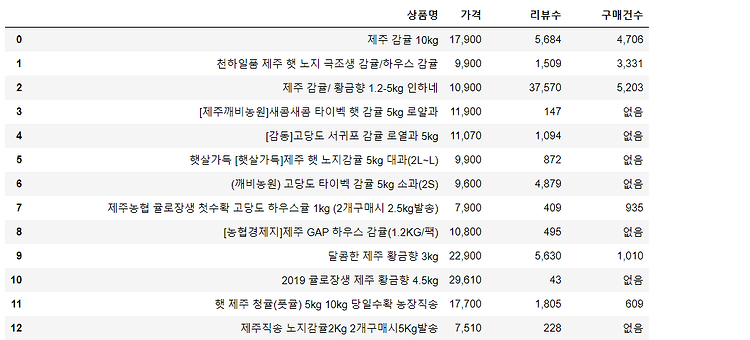
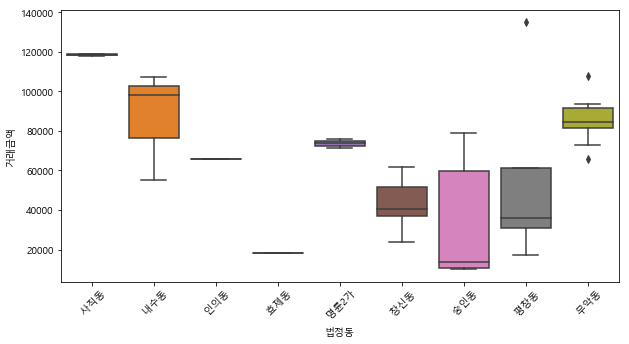
Hyper Parameters : 개념, 종류, 팁
이번 포스팅에서는 하이퍼 파라미터에 대해 알아보겠습니다. 하이퍼 파라미터는 모델을 학습할 떄, 외적인 요소로 학습에 영향을 미치는 파라미터들입니다. 대표적으로 어떤 것들이 있고, 어떠한 것인지 매우 간략하게 알아보았습니다. learning rate : 런닝 레이트 보통 런닝 레이트를 학습률이라고 이해하면 됩니다. 위 함수들은 대표적인 최적화 함수들입니다. 따라서, 최적화를 진행할 떄, 어느정도로 학습을 하여 진행을 할지 정하는 값들입니다. 너무 크면, 최적화할 곳을 지나가버리는 단점이 있습니다. 하지만, 너무 작아도, 최적화할 곳을 찾지 못하고, 머무르는 현상이 있을 수 있습니다. 따라서, 여러 대표값들을 적용해 학습을 진행해야 합니다. overfitting : 오버피팅 트레이닝을 할 떄, 조심해야 하는..