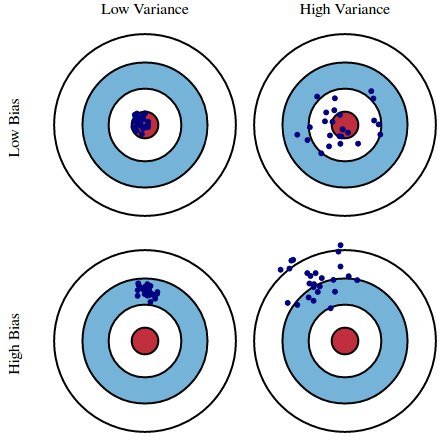
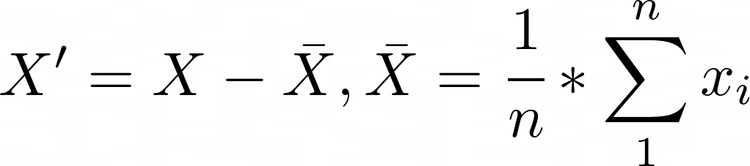MSE f가 제대로 추정되었는지 평가하기 위함입니다. 예측한 값이 실제 값과 유사한지 평가하는 척도가 필요합니다. MSE ( mean squared error) 는 모형의 적합성(오류)를 평가하는 지표입니다. MSE는 실제 종속 변수와 예측한 종속 변수간의 차이를 의미합니다. 따라서 작을수록 좋지만, 과도하게 줄이면 과적합의 오류를 범할 가능성이 있습니다. 따라서, 검증 집합의 MSE를 줄이는 방향으로 f를 추정합니다. MAPE mean absolute percentage error는 모형의 적합성을 평가하는 지표입니다. MAPE는 퍼센트 값을 가지며 0에 가깔우수록 회귀 모형의 성능이 좋다고 할 수 있습니다. 0% ~ 100% 사이의 값을 가져 이해하기 쉬울 수 있습니다. 성능 비교 해석이 또한 가능합..