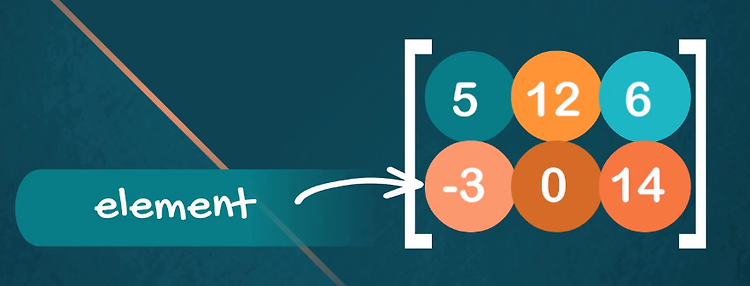
패키지 임포트 import numpy as np import tensorflow as tf import tensorflow_datasets as tfds 이번 포스팅에서도 동일하게 패키지 임포트를 진행합니다. 패키지를 설치하는 방법이나 활용하는 방법은 이전 포스팅을 참조해주세요. 데이터 전처리 mnist_dataset, mnist_info = tfds.load(name='mnist', with_info=True, as_supervised=True) mnist_train, mnist_test = mnist_dataset['train'], mnist_dataset['test'] num_validation_samples = 0.1 * mnist_info.splits['train'].num_examples nu..