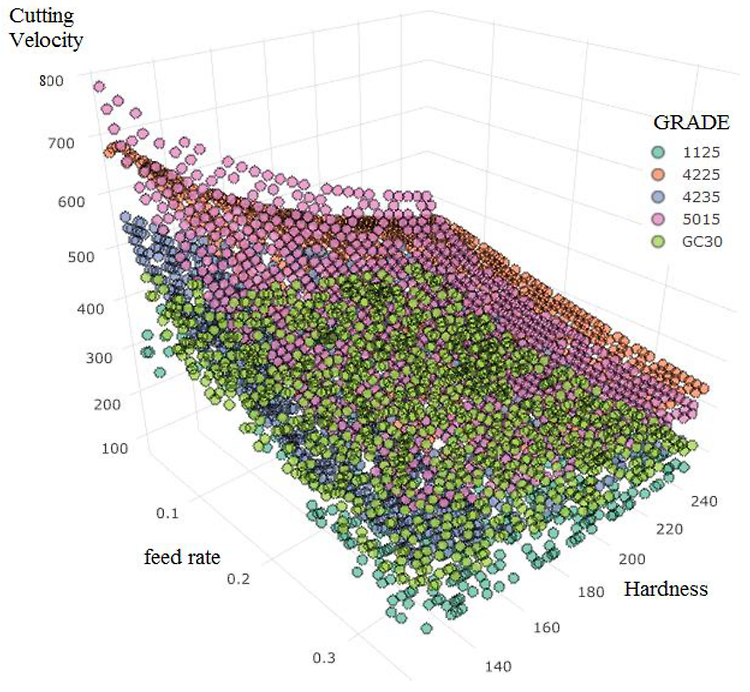
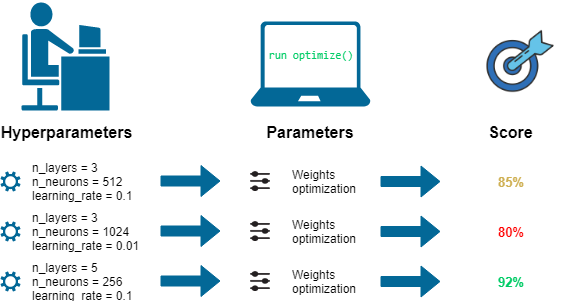
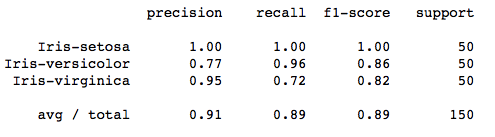
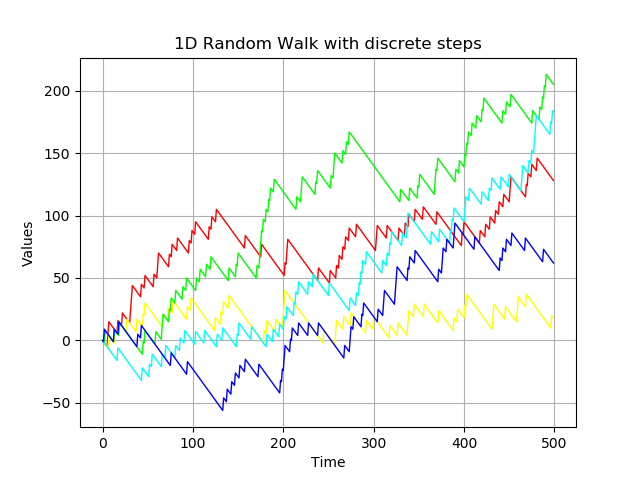
머신러닝 모델 구현 파이썬과 Scikit-learn 라이브러리를 이용해 주가방향을 예측할 수 있는 간단한 주가 방향 예측변수를 구현합니다. 핵심 아이디어는 전날의 종가 또는 거래량 데이터를 이용해 다음날의 주가 방향을 예측하는 것입니다. 사용자는 입력 변수로 종가나 거래량 중 하나를 사용할 수 있습니다. 또는 2개를 모두 사용할 수 있습니다. 또한, 하루 전의 데이터를 기준으로 예측할지, 며칠 전의 데이터를 기준으로 예측할지 선택할 수 있습니다. 데이터셋하나의 데이터 셋을 만들고, 만들어진 데이터 셋을 일정 비율로 나누어 학습과 테스트에 사용합니다. 학습용 데이터셋은 주가방향 예측변수를 학습시키기 위해 사용하는 것으로, 이 데이터를 이용해 각 주가방향 예측변수 모델을 완성합니다. 테스트용 데이터셋은 학습..